
BatchNorm与LayerNorm的部署优化加速
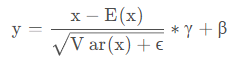
两者的计算方式相同,区别在计算的维度和统计数据是否可以离线获得。
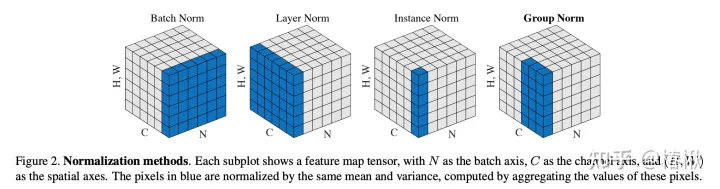
BatchNorm使用Batch维度参与了均值和方差的计算。训练时,BatchNorm会根据训练数据更新统计值;在推理时,方差、均值、 γ 和 β 都是固定的参数。这导致训练和推理时行为的不匹配,但是给推理时优化带来了机会。BatchNorm一般用在一个Conv2d操作之后,对于这种矩阵计算,固定的参数可以在编译器优化时将其提前融合进权重(守夜人:TVM设计与架构:Relay Pass,深度学习编译器的高层次优化在做什么)。nn.BatchNorm2d(num_features)中的num_features一般是输入数据的第二维(假设输入数据的维度为(N,num_features, H, W)),一层BatchNorm2d的γ 和 β数量等于num_features。在计算方差和均值时,将除了轴num_features以外的所有轴的元素放一起,取均值和方差后,乘以对应的γ 和 β(共享)。
LayerNorm一般用特征的最后一维计算方差和均值。在训练时只对 γ 和 β 进行统计;推理时只有 γ 和 β是提前已知的,方差和均值需要在线计算,因此不能和Conv或Matmul融合。nn.LayerNorm(normalized_shape)中的normalized_shape是最后几维(假设输入数据的维度为(N1,N2,normalized_shape),normalized_shape表示多个维度,CV和NLP中维度数不同)),一层LayerNorm的γ 和 β数量等于normalized_shape。在计算方差和均值时,将normalized_shape中的元素放在一起,归一化后,乘以对应的γ 和 β(每个元素对应的都不同)。在transformer中输入一般是(batch, sentence_length, embedding_dim),则LayerNorm层有embedding_dim个参数γ和β。也就是对于输入的单词序列,LN是对一个单词的embedding向量进行归一化的。
对于BatchNorm的优化,开启编译器的优化后,该层直接融合进Conv或Matmul权重中。
对于LayerNorm的优化,可以将其进行数学简化,原始的方差计算方式如下:
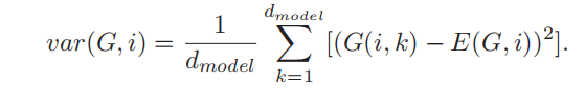
需要先算出均值,之后再进行差的平方的累加。总共两个循环。
根据下面这个原理:

可以将方差计算公式更新为
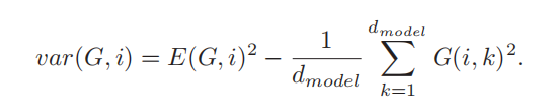
在计算均值时同时计算平方的均值,在一个循环就可以得到方差。
除了上述这种数学变换,不改变LayerNorm本来计算方式的方法,还有许多替代LayerNorm的方式。
如
Zhang B, Sennrich R. Root mean square layer normalization[J]. Advances in Neural Information Processing Systems, 2019, 32 代码:https://github.com/bzhangGo/rmsnorm.

Nguyen T Q, Salazar J. Transformers without Tears: Improving the Normalization of Self-Attention[C]//Proceedings of the 16th International Conference on Spoken Language Translation. 2019.代码:https://github.com/tnq177/transformers_without_tears.
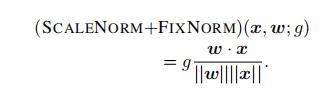
这些方法涉及更改模型,需要重新训练模型。
