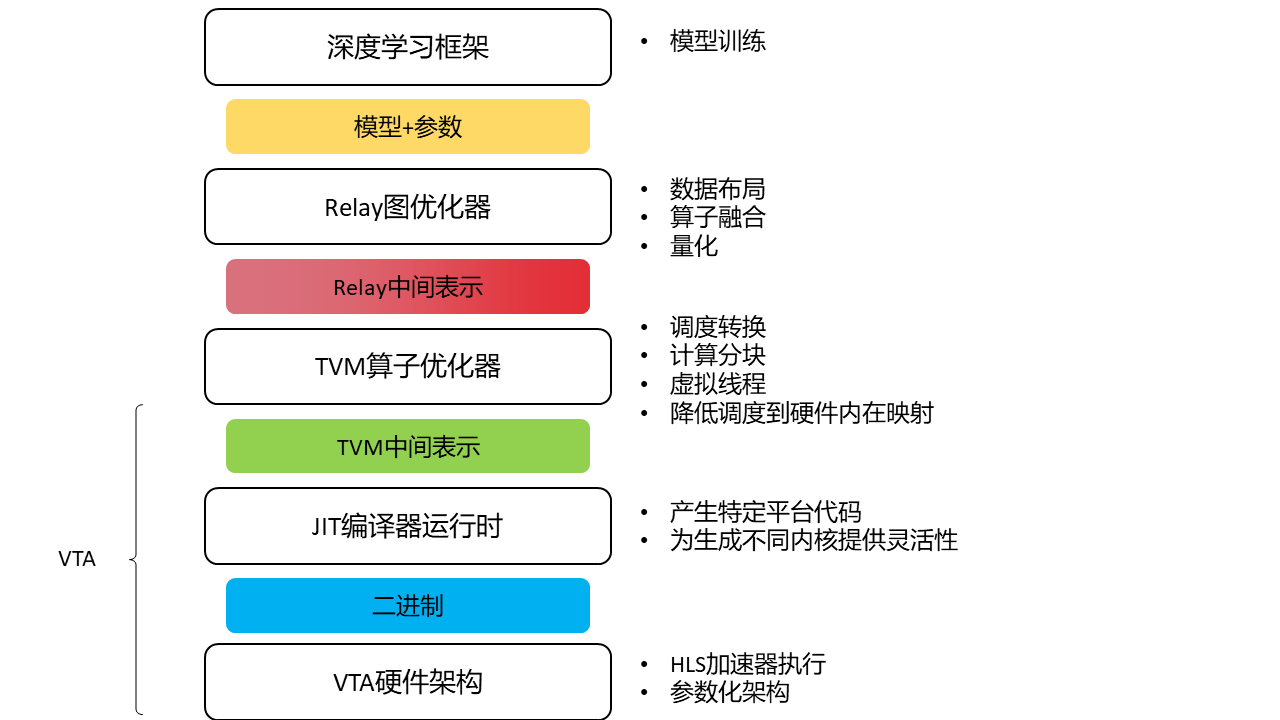
pass的作用
pass是编译器中用来对程序进行优化或分析的步骤,一个程序通常要经过多个pass,每个pass也可能执行多遍。关于TVM中的pass机制,请参考TVM的官方文档:
https://tvm.apache.org/docs/arch/pass_infra.htmltvm.apache.org/docs/arch/pass_infra.html
本文粗略统计了Relay高层次pass,主要想搞明白在高层次计算图优化中,编译器都做了哪些事。
关于pass执行前后程序的变化,可以参考relay的测试文件夹,文中示例均来自tvm/tests/python/relay/ ,由于精力有限,我只选取个别进行了输入输出的对比。
pass统计
DeadCodeElimination
| 名称 |
中文名 |
作用 |
备注 |
| DeadCodeElimination |
死节点消除 |
删除未被使用到的表达式 |
实现在tvm/src/relay/transforms/dead_code.cc |
实现流程应该是用UsageVisitor遍历每个节点,计数每个节点被用到的次数,当其为0时,在EliminatorMutator中将其去除。(这里没有详细探究实现细节,仅凭类名和函数名做合理猜测,可能与真实实现有出入,若想了解其具体实现,请参阅源代码,下面的pass同)
LazyGradientInit
| 名称 |
中文名 |
作用 |
备注 |
| LazyGradientInit |
梯度延迟初始化 |
减小梯度张量的内存开销,对ones, ones_like, zeros, zeros_like 这些算子只有使用到时再实例化 |
实现在tvm/src/relay/transforms/lazy_gradient_init.cc |
FoldConstant
| 名称 |
中文名 |
作用 |
备注 |
| FoldConstant(还有个FoldConstantExpr,针对常量表达式) |
常量折叠 |
折叠relay中的常量。 |
实现tvm/src/relay/transforms/fold_constant.cc |
这里代码中注释专门强调与QNN(TVM中导入已量化模型的框架)有关,QNN有些静态子图不能盲目折叠。
SplitArgs
| 名称 |
中文名 |
作用 |
备注 |
| SplitArgs |
分割参数 |
将有大量参数的函数分割成小块 |
实现tvm/src/relay/transforms/split_args.cc |
根据对应python文件的注释,该pass在常量折叠时使用
FuseOps
| 名称 |
中文名 |
作用 |
备注 |
| FuseOps(其逆操作为DefuseOps) |
算子融合 |
按照规则将算子融合为复合算子 |
实现tvm/src/relay/transforms/fuse_ops.cc |
在TVM中每个算子都有个类型,论文中是injective(1对1映射、如add、exp)、reduction(多对少的映射,如sum、max、min)、complex-out-fusable(逐元素复用映射到输出,比如conv2d)、opaque(不能融合,比如sort),融合规则如下
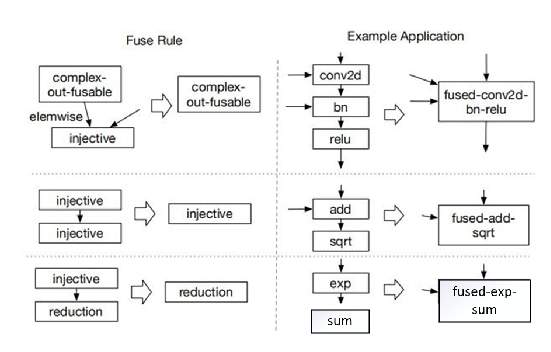
不晓得现在融合方式有没有变(代码太复杂了,短时间没有理清(T_T)
| 名称 |
中文名 |
作用 |
备注 |
| ToBasicBlockNormalForm |
将表达式转换为基本块范式 |
|
实现tvm/src/relay/transforms/to_basic_block_normal_form.cc |
| 名称 |
中文名 |
作用 |
备注 |
| ToANormalForm |
转换为A范式 |
将图范式转换为A范式的形式 |
tvm/src/relay/transforms/to_a_normal_form.cc |
google了一下A -Norm,是函数式编译器中程序的中间表示
为什么这么做可参阅这里:
https://matt.might.net/articles/a-normalization/
ToCPS
| 名称 |
中文名 |
作用 |
备注 |
| ToCPS |
转换为CPS(continuation passing style) |
将表达式转换为连续传递风格 |
tvm/src/relay/transforms/to_cps.cc |
关于CPS,戳这里https://en.wikipedia.org/wiki/Continuation-passing_style
| 名称 |
中文名 |
作用 |
备注 |
| ToGraphNormalForm |
转换为图范式 |
将A范式转换为图范式 |
tvm/src/relay/transforms/to_graph_normal_form.cc |
PartialEval
| 名称 |
中文名 |
作用 |
备注 |
| PartialEval |
部分求值 |
在编译时做尽可能多的计算,减少运行时的开销 |
tvm/src/relay/transforms/partial_eval.cc |
SimplifyInference
| 名称 |
中文名 |
作用 |
备注 |
| SimplifyInference |
简化推理 |
对各种归一化层做了重写 |
tvm/src/relay/transforms/simplify_inference.cc |
对batch_norm、dropout、instance_norm、layer_norm、group_norm、l2_norm做了重写
Example:tvm/tests/python/relay/test_pass_simplify_inference.py
# 原始输入
def @main(%x: Tensor[(10, 10), float32], %gamma: Tensor[(10), float32], %beta: Tensor[(10), float32], %moving_mean: Tensor[(10), float32], %moving_var: Tensor[(10), float32]) {
%0 = add(%x, 1f);
%1 = nn.batch_norm(%0, %gamma, %beta, %moving_mean, %moving_var, epsilon=0.01f);
%2 = %1.0;
%3 = nn.dropout(%2);
%3.0
}
#执行该pass
def @main(%x: Tensor[(10, 10), float32] /* ty=Tensor[(10, 10), float32] */, %gamma: Tensor[(10), float32] /* ty=Tensor[(10), float32] */, %beta: Tensor[(10), float32] /* ty=Tensor[(10), float32] */, %moving_mean: Tensor[(10), float32] /* ty=Tensor[(10), float32] */, %moving_var: Tensor[(10), float32] /* ty=Tensor[(10), float32] */) -> Tensor[(10, 10), float32] {
%0 = add(%moving_var, 0.01f /* ty=float32 */) /* ty=Tensor[(10), float32] */;
%1 = sqrt(%0) /* ty=Tensor[(10), float32] */;
%2 = divide(1f /* ty=float32 */, %1) /* ty=Tensor[(10), float32] */;
%3 = add(%x, 1f /* ty=float32 */) /* ty=Tensor[(10, 10), float32] */;
%4 = multiply(%2, %gamma) /* ty=Tensor[(10), float32] */;
%5 = negative(%moving_mean) /* ty=Tensor[(10), float32] */;
%6 = multiply(%5, %4) /* ty=Tensor[(10), float32] */;
%7 = multiply(%3, %4) /* ty=Tensor[(10, 10), float32] */;
%8 = add(%6, %beta) /* ty=Tensor[(10), float32] */;
add(%7, %8) /* ty=Tensor[(10, 10), float32] */
}
|
FastMath
| 名称 |
中文名 |
作用 |
备注 |
| FastMath |
快速数值计算 |
将非线性激活函数用更快的近似方法代替 |
tvm/src/relay/transforms/fast_math.cc |
包括exp(自然指数)、erf(误差函数)、tanh、softmax的fast版本
DynamicToStatic
| 名称 |
中文名 |
作用 |
备注 |
| DynamicToStatic |
动态转静态 |
若动态算子的输入是静态,将其转换为静态算子,重新执行类型推理和常量折叠 |
tvm/src/relay/transforms/dynamic_to_static.cc |
包含算子:reshape、squeeze、tile、topk、broadcast_to、zeros、ones、one_hot、image.resize2d、full、nn.upsampling、nn.upsampling3d、nn.pad、strided_slice、sparse_to_dense
InferType
| 名称 |
中文名 |
作用 |
备注 |
| InferType(InferTypeLocal类似) |
推断类型 |
填入明确的类型信息 |
tvm/src/relay/transforms/type_infer.cc |
EliminateCommonSubexpr
| 名称 |
中文名 |
作用 |
备注 |
| EliminateCommonSubexpr |
消除公共子表达式 |
若多个表达式是相同(属性相同且输入相同)的值且在多处使用,创建一个公共的变量替换这些表达式 |
tvm/src/relay/transforms/eliminate_common_subexpr.cc |
CombineParallelConv2D
| 名称 |
中文名 |
作用 |
备注 |
| CombineParallelConv2D(CombineParallelBatchMatmul类似) |
合并并行卷积 |
将共享相同输入节点和相同参数的卷积(除了输出通道的数量可以不同)替换为单一的卷积。新的2d卷积的权重是原始权重的concat。conv2d之后的加法广播运算也会尽可能合并。这可以防止在有多个卷积分支的网络中启动多个内核,如Inception。 |
tvm/src/relay/transforms/combine_parallel_conv2d.cc |
CombineParallelDense
| 名称 |
中文名 |
作用 |
备注 |
| CombineParallelDense |
合并并行Dense层 |
取代了共享相同输入节点、相同形状、没有定义 “ units “的dense操作,只用一个batch MM就可以。 这可以防止在有多个dense分支的网络中启动多个内核,例如BERT |
tvm/src/relay/transforms/combine_parallel_dense.cc |
FoldScaleAxis
| 名称 |
中文名 |
作用 |
备注 |
| FoldScaleAxis(ForwardFoldScaleAxis、BackwardFoldScaleAxis类似) |
折叠在轴上的缩放 |
当某个轴上带有放缩时,将其融合进dense或conv2d的权重 |
tvm/src/relay/transforms/fold_scale_axis.cc |
# tvm/tests/python/relay/test_pass_fold_scale_axis.py
#最初的输入
def @main(%x: Tensor[(2, 4), float32] /* ty=Tensor[(2, 4), float32] */, %weight: Tensor[(3, 4), float32] /* ty=Tensor[(3, 4), float32] */, %in_bias: Tensor[(4), float32] /* ty=Tensor[(4), float32] */) -> Tensor[(2, 3), float32] {
%0 = multiply(%x, meta[relay.Constant][0] /* ty=Tensor[(4), float32] */) /* ty=Tensor[(2, 4), float32] */;
%1 = nn.relu(%0) /* ty=Tensor[(2, 4), float32] */;
%2 = add(%1, %in_bias) /* ty=Tensor[(2, 4), float32] */;
nn.dense(%2, %weight, units=None) /* ty=Tensor[(2, 3), float32] */
}
#结果
def @main(%x: Tensor[(2, 4), float32] /* ty=Tensor[(2, 4), float32] */, %weight: Tensor[(3, 4), float32] /* ty=Tensor[(3, 4), float32] */, %in_bias: Tensor[(4), float32] /* ty=Tensor[(4), float32] */) -> Tensor[(2, 3), float32] {
%0 = nn.relu(%x);
%1 = divide(%in_bias, meta[relay.Constant][0] /* ty=Tensor[(4), float32] */);
%2 = add(%0, %1);
%3 = multiply(%weight, meta[relay.Constant][0] /* ty=Tensor[(4), float32] */);
nn.dense(%2, %3, units=None)
}
|
口头验证一下结果:
输入的计算流程相当于:假设f是relu函数
AX -> f(AX) -> f(AX)+B ->W(f(AX)+B) = Wf(AX)+WB
执行该pass后:
f(X) -> B/A -> f(X)+B/A -> WA -> WA(f(X)+B/A) =WA(fX)+WB 由于Relu是留下正数,所以上下两个的计算结果是相等的
通过该pass,将在运行时对输入的计算转换为对权重的计算,然后这部分可以在编译时就对权重进行修改,从而节约了运行时开销。BatchNorm分解后也可以用该pass融合进权重。
CanonicalizeOps
| 名称 |
中文名 |
作用 |
备注 |
| CanonicalizeOps |
规范化算子 |
将算子转换为其简化版本 |
tvm/src/relay/transforms/canonicalize_ops.cc |
在实现中仅涉及bias_add_op,将其转换为expand_dims+boradcast_add
AlterOpLayout
| 名称 |
中文名 |
作用 |
备注 |
| AlterOpLayout(ConvertLayout类似) |
替换算子布局 |
用于计算自定义布局的卷积或其他通用权重的预变换。 |
tvm/src/relay/transforms/alter_op_layout.cc |
AutoSchedulerLayoutRewrite
| 名称 |
中文名 |
作用 |
备注 |
| AutoSchedulerLayoutRewrite(MetaScheduleLayoutRewrite类似) |
AutoScheduler布局重写 |
根据AutoScheduler(TVM的无模板自动调优器)生成的tile结构进行对应权重的存储布局重写 |
tvm/src/relay/transforms/auto_scheduler_layout_rewrite.cc |
包括Conv2D、Conv2DWinograd、Conv3D、Matmul、Dense、BatchMatmul
Legalize
| 名称 |
中文名 |
作用 |
备注 |
| Legalize |
合法化 |
用另一个表达式替换一个表达式,以实现目标平台相关的优化 |
tvm/src/relay/transforms/legalize.cc |
该pass主要用于QNN,关于该pass的作用可查阅QNN的论文。举例几个QNN合法化的算子:
路径在tvm/src/relay/qnn/op/
qnn.dense、qnn.batch_matmul、qnn.conv2d等
CanonicalizeCast
| 名称 |
中文名 |
作用 |
备注 |
| CanonicalizeCast |
规范化cast |
规范化cast表达式,使得算子融合更有效 |
tvm/src/relay/transforms/canonicalize_cast.cc |
EtaExpand
| 名称 |
中文名 |
作用 |
备注 |
| EtaExpand |
|
为构造函数添加抽象,或者给一个函数添加全局变量 |
tvm/src/relay/transforms/eta_expand.cc |
PartitionGraph
| 名称 |
中文名 |
作用 |
备注 |
| PartitionGraph |
划分图 |
根据插入的标注节点(即compiler_begin和compiler_end),将一个输入函数分割成多个函数。这些节点被用作边界,将Relay函数划分为多个区域,可以卸载到不同的加速器后端。 每一个被分割的函数,也就是区域,都将被视为外部函数,并且它们将使用所提供的编译器进行代码生成。 |
tvm/src/relay/transforms/partition_graph.cc |
该pass的作用可见专栏中的BYOC
Inline
| 名称 |
中文名 |
作用 |
备注 |
| Inline |
内联 |
将全局函数内联到Relay IR Module |
tvm/src/relay/transforms/inline.cc |
RemoveUnusedFunctions
| 名称 |
中文名 |
作用 |
备注 |
| RemoveUnusedFunctions |
删除未用到的函数 |
|
tvm/src/relay/backend/vm/removed_unused_funcs.cc |
SimplifyExpr
| 名称 |
中文名 |
作用 |
备注 |
| SimplifyExpr |
简化表达式 |
简化Relay表达式 |
tvm/src/relay/transforms/simplify_expr.cc |
主要包含以下简化:
ConcretizeZerosLikeRewrite
ConcretizeOnesLikeRewrite
ConcretizeFullLikeRewrite
ConcretizeReshapeLikeRewrite
ConcretizeCollapseSumLikeRewrite
ConcretizeBroadcastToLikeRewrite
ConcretizeCastLikeRewrite
SimplifyRSqrt
EliminateIdentityRewrite
SimplifyReshape
SimplifyTranspose
SimplifySameCast
SimplifyConsecutiveCast
FullElementwise
SwitchAddMultiply
SimplifyAdjacentMultiplyOrAdd
SimplifyDQArgMax
SimplifyDQArgMin
SimplifyDQArgSort
SimplifyClipAndConsecutiveCast
SimplifyCastClip
|
RelayToTIRTargetHook
| 名称 |
中文名 |
作用 |
备注 |
| RelayToTIRTargetHook |
Relay到TIR目标的hook |
处理已在IRModule内的函数上注册的目标hook |
tvm/src/relay/transforms/target_hooks.cc |
ManifestAlloc
| 名称 |
中文名 |
作用 |
备注 |
| ManifestAlloc(ManifestLifetimes类似) |
表现内存分配 |
|
tvm/src/relay/transforms/memory_alloc.cc |
PlanDevices
|
中文名 |
作用 |
备注 |
| PlanDevices |
计划设备 |
确定每个relay子表达式运行和存储结果的虚拟设备(VirtualDevice) |
tvm/src/relay/transforms/device_planner.cc |
FlattenAtrousConv
|
中文名 |
作用 |
备注 |
| FlattenAtrousConv |
展平空洞卷积 |
这种转换将空洞卷积扁平化,它对应于操作序列”space_to_batch_nd”->”conv2d””batch_to_space_nd”,并将它们转换成带有修改过的 “dilation “和重新计算的 “padding “参数的卷积子图。 |
tvm/src/relay/transforms/flatten_atrous_conv.cc |
AnnotateUsedMemory
|
中文名 |
作用 |
备注 |
| AnnotateUsedMemory |
标注使用的存储 |
通过分析每个函数调用的输入/输出张量的有效性并计算这些张量所需的总内存量,标注每个函数调用点的最小所需内存。不支持动态类型。 |
tvm/src/relay/backend/annotate_used_memory.cc |
示例:
Before:
def @main(%input: Tensor[(1, 2, 2, 4), int8]) -> Tensor[(1, 2, 2, 4), int8] {
let %x_0 = fn (%x: Tensor[(1, 2, 2, 4), int8], Primitive=1) -> Tensor[(1, 2, 2, 4), int8] {
nn.max_pool2d(%x, pool_size=[1, 1], padding=[0, 0, 0, 0])
};
let %x_1 = %x_0(%input);
%x_1
}
After:
def @main(%input: Tensor[(1, 2, 2, 4), int8], io_used_memory=32) -> Tensor[(1, 2, 2, 4), int8] {
let %x_0: fn (%x: Tensor[(1, 2, 2, 4), int8], Primitive=1, used_memory=[32]) -> Tensor[(1, 2,
2, 4), int8] {
nn.max_pool2d(%x, pool_size=[1, 1], padding=[0, 0, 0, 0])
};
let %x_1: Tensor[(1, 2, 2, 4), int8] = %x_0(%input);
%x_1
}
|
CapturePostDfsIndexInSpans
|
中文名 |
作用 |
备注 |
| CapturePostDfsIndexInSpans |
|
|
tvm/src/relay/transforms/capture_postdfsindex_in_spans.cc |
AnnotateMemoryScope
|
中文名 |
作用 |
备注 |
| AnnotateMemoryScope |
标注内存范围 |
|
tvm/src/relay/transforms/annotate_texture_storage.cc |
RemoveStandaloneReshapes
|
中文名 |
作用 |
备注 |
| RemoveStandaloneReshapes |
删除独立reshape |
|
tvm/src/relay/transforms/remove_standalone_reshapes.cc |
Pass简要分类
粗糙的分类,很可能不正确,仅供参考
| 主要作用 |
包含pass |
| 化简,去除运行时冗余,加快计算 |
DeadCodeElimination、LazyGradientInit、FoldConstant、SplitArgs、PartialEval、SimplifyInference、FastMath、DynamicToStatic、EliminateCommonSubexpr、FoldScaleAxis、CanonicalizeOps、CanonicalizeCast、RemoveUnusedFunctions、SimplifyExpr、RemoveStandaloneReshapes |
| 程序语言形式相关 |
ToBasicBlockNormalForm、ToANormalForm、ToCPS、ToGraphNormalForm、InferType、EtaExpand、Inline |
| 编译器相关的,设备、存储 |
AlterOpLayout、AutoSchedulerLayoutRewrite、PartitionGraph、RelayToTIRTargetHook、ManifestAlloc、AnnotateUsedMemory、AnnotateMemoryScope |
| 算子内核生成、改进的 |
FuseOps、CombineParallelConv2D、CombineParallelDense、FlattenAtrousConv |
| 执行检查 |
Legalize |
有些pass我也没搞懂啥作用,上述表格对应位置就空下了,在此抛砖引玉。