TVM第三方论文调研(二):KunlunTVM,昆仑芯片的TVM编译器扩展
论文信息
出处:J. Zeng, M. Kou, and H. Yao, “KunlunTVM: A Compilation Framework for Kunlun Chip Supporting Both Training and Inference,” in Proceedings of the Great Lakes Symposium on VLSI 2022, Irvine CA USA, Jun. 2022, pp. 299–304. doi: 10.1145/3526241.3530316.
简介:为昆仑芯片开发的端到端编译器,基于TVM扩展,名为KunlunTVM,支持在昆仑芯片上的训练和推理任务。该方法针对不同后端的TVM框架是通用且可扩展的,可以借鉴其设计思路,学习如何为新后端添加编译器工具链。
主要贡献:
- 在昆仑芯片上的基于TVM的端到端编译器,可支持各种现代神经网络模型
- 训练计算图优化策略,旨在提高训练性能
- 专用的内存管理算法,针对昆仑芯片的分层存储提升了内存分配和访问性能
KunlunTVM概述
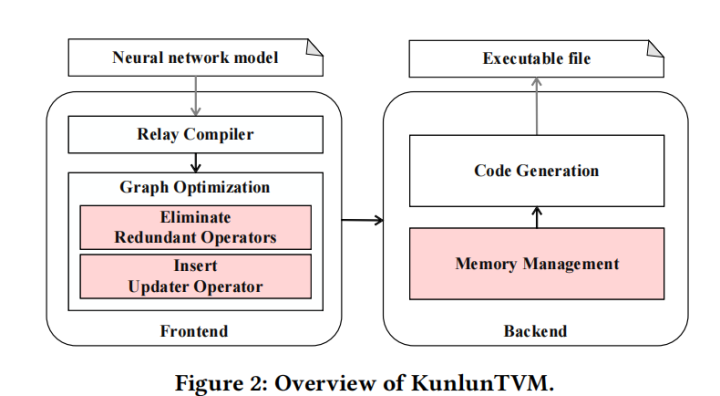
前端:
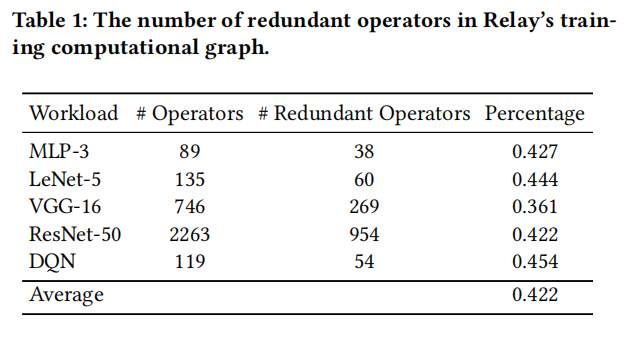
1.直接采用relay生成的反向传播计算图存在冗余算子,在训练时对性能有很大负面影响。改进:因此KunlunTVM在高层图优化时提出了一种冗余算子消除的方法来进行了优化。
2.在relay中,一旦变量被定义就无法修改,因此不支持在训练过程中更新relay中的参数变量。可能的解决方法是更新在计算图之外的权重参数,即更新host端(CPU)数据。在训练时从device端(昆仑芯片)获得梯度,根据梯度下降法更新host上的权重,host再将更新的权重参数送往device。该方法在host和device之间引入了不必要的数据开销。改进:在训练计算图中插入名为updater的算子,直接更新device端数据,避免数据传输。
后端:
1.TVM的默认内存管理方法在每次训练迭代分配、释放所需的内存,造成冗余。改进:设计了专用的基于池的内存管理方法。
2.使用TVM的BYOC机制进行代码生成
图优化策略
冗余算子消除
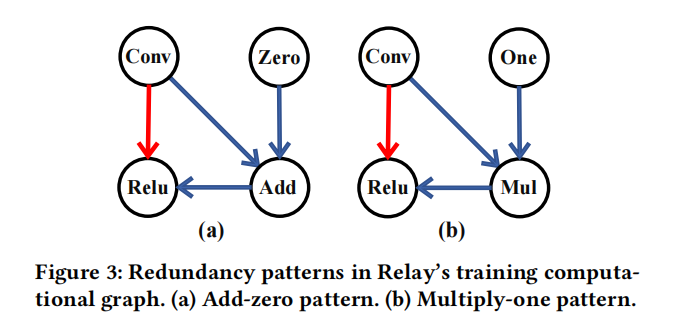
主要有加0和乘1这两种冗余,上图蓝色为冗余操作,红色为消除冗余后操作。
下图为冗余算子占的比例:不太清楚这种冗余在反向传播计算图中出现的原因,论文中也没有解释,或许是对自己求了一次导???
updater算子
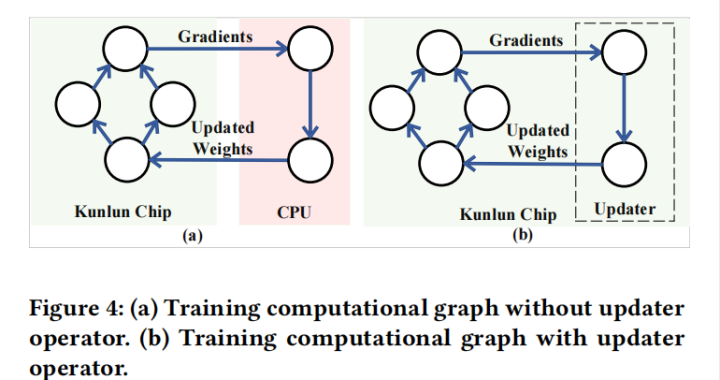
如上图,左边为冗余的更新方式,需要经过一遍CPU将更新后的值再送往芯片上。右边为插入Updater算子后的更新方式,直接在芯片上进行了修改。relay将算子看做函数调用,可以将其实现分派到低级编译器中。在这里updater在relay是个函数调用,具体实现是昆仑芯片提供的API,连接到芯片的动态链接库中。
内存管理
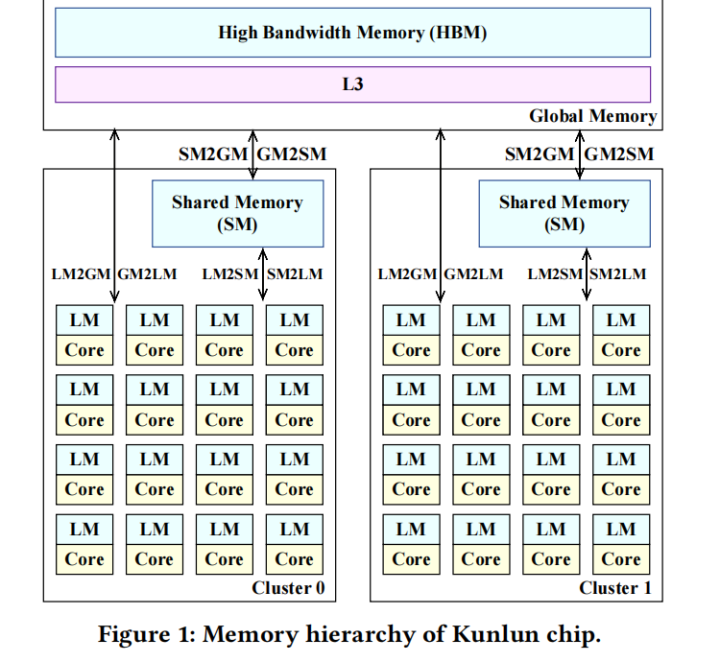
上图为昆仑芯片的存储架构。有全局存储、共享存储、本地存储。每个XPU核只能直接访问本地存储,意味着从CPU传递到XPU核的数据必须经过全局存储,带来了重复的内存分配和释放。
传统的内存池算法
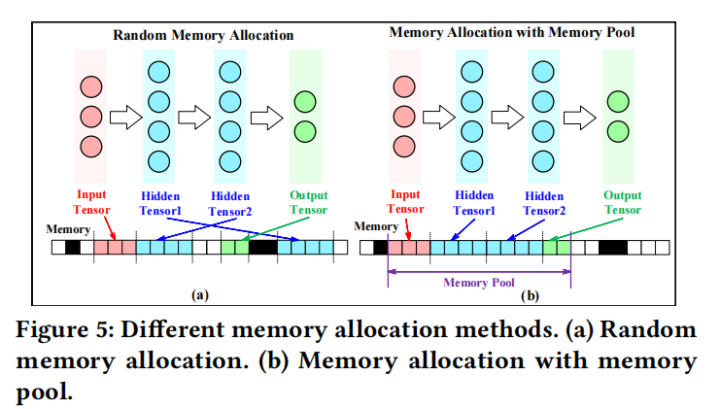
上图左边为随机分配,地址较分散,无法有效利用cache机制的局部性来加速。右边是基于池的分配方法,地址连续。但是由于昆仑芯片容量受限,不允许传统基于池的方法分配大量连续内存。
专用内存管理算法
该方法主要包括训练计算图的遍历和内存分配两个步骤。
图遍历:
根据计算图的定义,节点是算子或数据,连线是数据依赖关系。
根据拓扑排序的方式(按照入度进行排序),将有访存需求的节点存入有序的list
内存分配:
遍历后,得到了算子的执行顺序和内存需求。然后,执行顺序和内存需求分别用于代码生成和内存分配。
基于池的方法根据图遍历获得的内存需求来分配内存池,避免了上述内存浪费。此外,所提出的基于池的方法在每次训练迭代中重用所分配的内存,避免了上述内存分配和释放中的冗余。
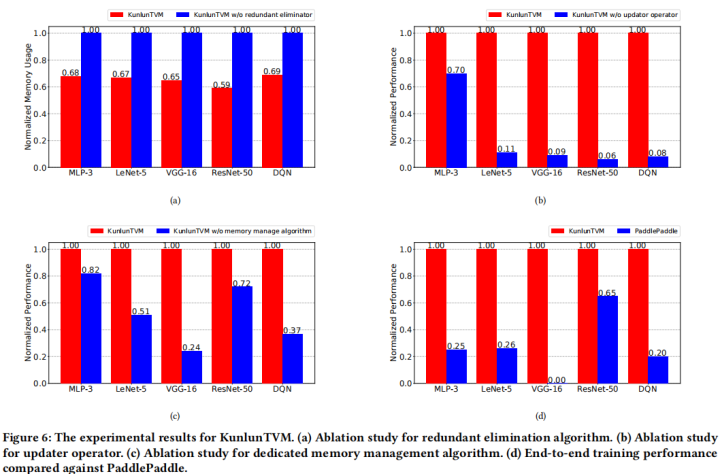
实验
设计了消融实验,分别测试了消除冗余、updater算子和内存管理的有效性。