TVM第三方论文调研(三) BYOC,将自己的硬件加速器对接深度学习编译器
论文信息
论文出处:Z. Chen et al., “Bring Your Own Codegen to Deep Learning Compiler.” arXiv, May 03, 2021. Accessed: Jun. 27, 2022. [Online]. Available: http://arxiv.org/abs/2105.03215
Motivation:深度学习加速器需要编译栈来将模型映射到指令集,如果每个加速器供应商都开发一个专用深度学习编译堆栈,无疑会带来巨大的成本,也无法利用现存的基础设施。该文提出了一个框架,允许用户重用现有的编译器中尽可能多的组件,只专注于专有的代码生成工具的开发。
主要贡献:
- 提出了一个统一的框架,允许不同的硬件加速器供应商通过以即插即用的方式集成他们的代码工具,复用尽可能多的硬件无关的优化
- 为开发人员提供了灵活的接口,以便1)对计算图进行标注和分区;2)对分区图应用特定于硬件的优化
- 平均2000行代码的集成方法的案例研究
另外,TVM文档中有该框架的教程,关键字即论文题目
框架设计与实现
编译流程如下:

白色的部分是深度学习编译器已有的,不同后端共享;灰色的部分是硬件相关的,需要为每个加速器定制。
流程:
1.模型加载,转换为统一的IR表示
2.硬件无关的计算图优化,常数折叠、算子简化等
3.图划分,划分为host和accelerator两个部分。
图划分
将模型切割为不同的子图,对加速器运行友好(例如加速器支持的算子,或者在加速器上执行效率更高的算子)的部分被卸载,其余部分仍然让host执行。深度学习编译器通常有多层IR,比如TVM的Relay和TensorIR,和MLIR(顾名思义),因此需要决定在哪个IR级别进行划分。
该框架在高层IR(即仍旧保留算子名称和属性的IR)进行划分,出于以下考虑:
1)一些硬件供应商手工制作了一个内核库。在这种情况下,唯一需要的信息是将每个算子映射到对应的内核的名称和属性,而不是由低级IR合并的硬件信息。
2)一些硬件供应商使用自己的低级IR,需要从高层IR转换
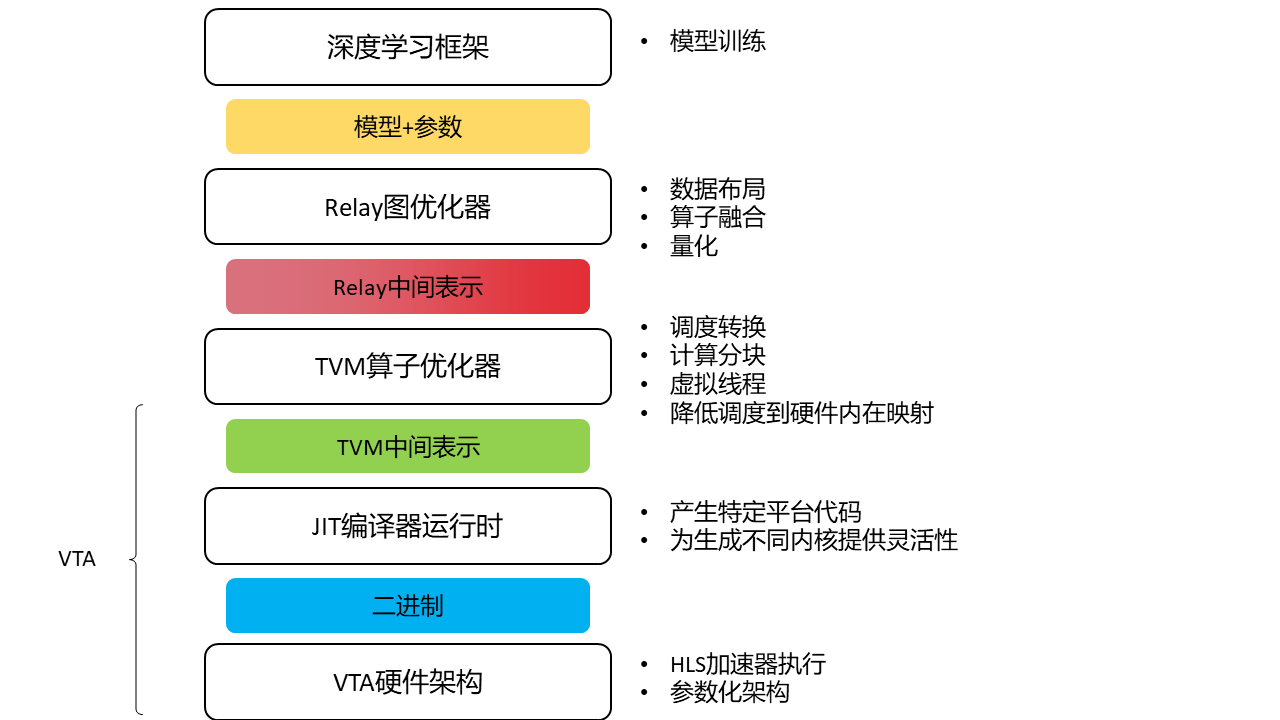
基于模式的分组:
许多硬件加速器使用指令执行算子。例如Conv2d、Add、Relu的序列通常可以映射到单个算子,以最小化处理中间结果的开销(算子融合)。因此,硬件供应商需要使用模式匹配算法来匹配IR节点序列,并用复合指令替换他们。
该框架提供了模式匹配机制,如下代码描述的匹配一个Conv2d-add-relu

通过上述匹配模式表,可以将图3(上)a转换为b
注解:
在根据模式将node进行分组后,下一步是根据编程模型指定支持的算子列表。例如下代码注册了一个函数,指示所有浮点类型的Conv2D节点被注释并卸载到MyAccel中

通过一组注解函数,在图中生成了多个区域,这些区域可以被卸载到目标加速器上,如上图3(c) 。
在上图例中将区域都卸载到一个目标MyAcc上,但该框架支持将区域卸载到多个目标上,并可以指定优先级,将算子卸载到最高优先级的目标上。
基于成本的划分:
贪心的合并支持的算子以进行充分的算子融合是理想的,但由于资源限制(如片上存储大小、计算单元数量),对于一些加速器来说不适用。除了注解外,该框架还提供另一种基于成本的划分。用户设置最大可融合的数量,例如将3N设为阈值,图3(c)中的区域应当分割为图3(d)中的区域1和3。
将一个区域从host卸载到device通常会引入数据传输和内核调用开销,如果没有耗时的计算,应该将区域留在host执行,该框架支持按用户指定的标准将区域回调到host上。
最后,每个可卸载区域被封装成一个单独的函数,并用一个target属性标记,该属性指示执行后端,如图3(e)。
特定加速器的处理
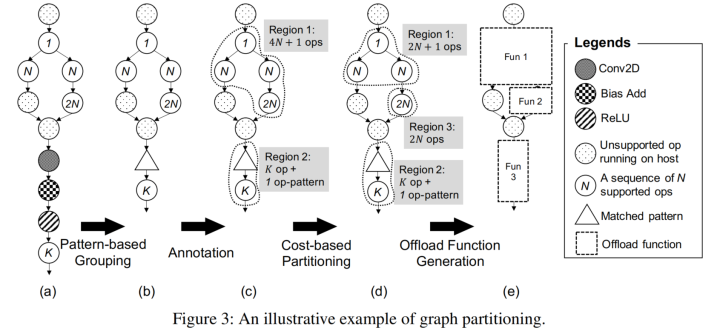
在划分之后,一个图被分割成多个不同后端处理的区域,在host上的区域可以有效利用从现有的深度学习编译器中进行的标准优化,然而卸载到加速器的区域可能需要一些特定于硬件的优化(例如融合、替换、存储布局转换、量化等),这些优化通常是专有的,无法在深度学习编译器中处理。
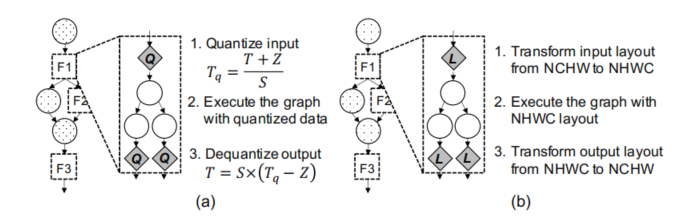
上图左边是量化,右边是存储布局转换。
代码生成
编译流的最后一步是代码生成。
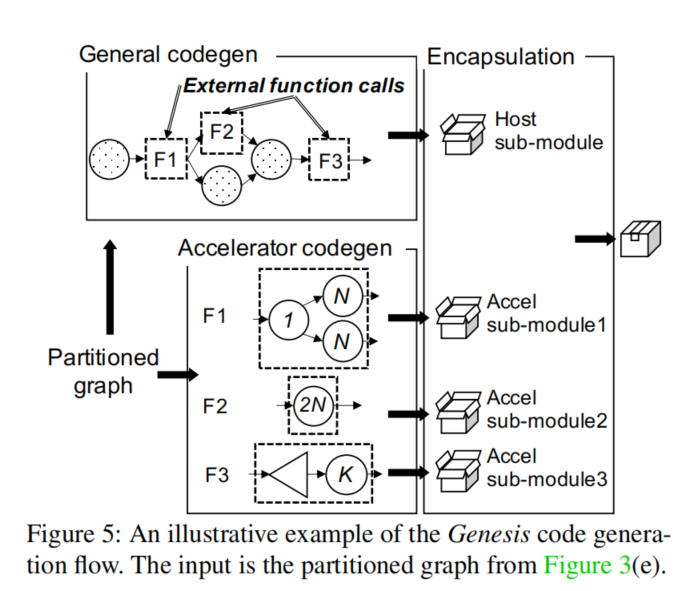
该框架通过遍历图并为每个图节点调用相应的代码生成来生成一个子模块。当遍历到host上的节点时,可以利用现有深度学习编译器中的代码生成,如TVM和XLA,它们能为通用设备(如CPU和GPU)生成代码。当遍历到特定target标注的节点(即划分函数)时,生成一个外部函数调用作为运行时内核调用的hook。同时调用加速器特定的代码生成,其包含了硬件供应商提供的代码生成工具和编译流,为该节点中的划分函数生成一个“加速器子模块”。
加速器子模块中生成的代码必须以一定的格式表示,以便在运行时可以被加速器的执行引擎消耗。该框架提供了一下代码生成格式:
- 标准图表示 使用json文件记录算子名称、属性和数据流,这种格式易读。例如NVIDIA TensorRT和Arm计算库使用该框架的json生成器来搭建与运行时之间的桥梁。
- 标准C代码
尽管选项1易于实现和部署,但它需要一个图引擎来包含所有受支持的算子的实现,这可能会导致较大的二进制大小。
该框架提供了一个标准的C代码生成器,可以发射内核库函数调用并将它们与host子模块链接在一起来支持加速器的专有内核库,这个解决方案简化了代码打包,因为host代码通常是兼容C的。当库函数调用成为host子模块一部分时,硬件供应商可以充分利用现有的运行时系统。
3. 自定义图表示
某些加速器有专用格式来表示神经网络,如ARM Ethos-N和Xilinx Vitis AI,为了满足这种需求,该框架提供了一组统一的API来定制序列化的代码格式:1)将生成的代码编译和序列化为一个bit流,以便其可以与其他子模块一起实例化;2)在运行时反序列化来自子模块的bit流
至此,针对DNN模型的编译和打包模块已经完成,之后进入运行时系统加载模块并执行推理。
运行时
运行时系统负责执行模型图的推理,并将算子和子图分发到目标平台。图执行引擎可以是一个简单的数据流图visitor,处理大多数CNN;也可以是一个虚拟机来执行字节码,处理现代模型中呈现出的动态性和控制流。
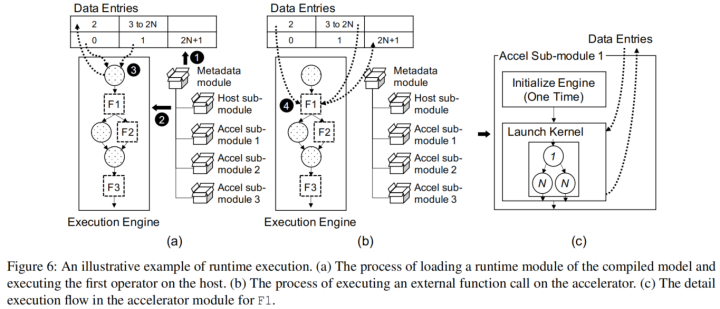
运行时系统流程如下:
- 初始化元数据模块
DNN模型的大量权重参数在推理时一般是常数,应该包含在运行时模块中。不同的子模块都需要这些权重,该框架提供了一个统一的模块来管理,称为元数据模块。如上图6(a)中,元数据模块被设计为一个包含所有常量、host子模块、加速器子模块的层次化模块。在初始化时,元数据模块将这些常量加载到运行时数据项中,这是在host或加速器上预分配的一组内存buffer。(如上图
6①)
除了权重常量外,数据项还维护了模型的输入、输出以及中间结果。由于划分函数(即算子融合后的复合算子)已经是外部函数调用。因此其中间结果不会在数据项中得到维护。
- 执行host上的图节点
当调用推理时,host子模块加载模型图并启动执行引擎(上图6②),开始依次执行图节点。如上图6③子模块可以直接访问数据项来读取输入,调用内核执行计算,将结果写入数据项。
- 执行加速器上的图节点
如上图6(b),host执行引擎执行F1,这是对加速器的外部函数调用(图6④)。执行细节如图6(c)。
执行过程包含两个步骤:1)加载模块后初始化硬件供应商定制的F1执行引擎;2)启动内核,与数据项做交互
案例研究
在TVM中实现了该框架。使用该框架集成了ARM Ethos-N处理器(2405行代码)、Xilinx Vitis AI(1924行代码)。还包括许多软件工具包,NVIDIA TensorRT(4403行代码),ARM计算库(2188行代码)、德州仪器深度学习工具(3085行代码)。
在进行案例研究前,带着以下几个问题:
- 相比于baseline,模型可获得的加速是多少?
- 有多少算子可以卸载到目标平台?
- 卸载图中的MAC占整个图的多少?
- 卸载开销是多少?
NVIDIA Jeston AGX Xavier GPUs
Jeston AGX Xavier包含一个512核的Volta GPU,两个深度学习加速器,一个8核的NVIDIA Carmel ARMv8.2 CPU。主要用于机器人、无人机和其他自主机器人。
本案例将TensorRT集成到框架中。TensorRT支持32bit全精度和16bit半精度,当运行具有全精度模型的半精度TensorRT内核时,利用引入的部分量化机制,将全精度输入数据实时转换为半精度。
将TVM内置CUDA代码生成作为baseline,不使用AutoTVM进行自动调优。
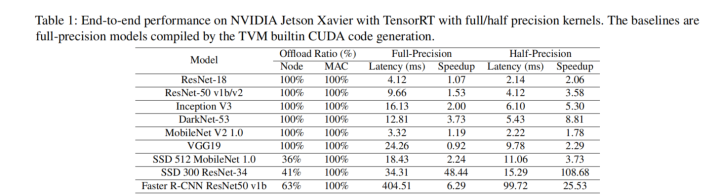
对于SSD和Faster RCNN,控制流和其他一些算子不支持,因此卸载率不是100%,但是所有的MAC都可以卸载到TensorRT上。
表2显示了在基于成本的划分之前和之后的子图数量以及端到端延迟。
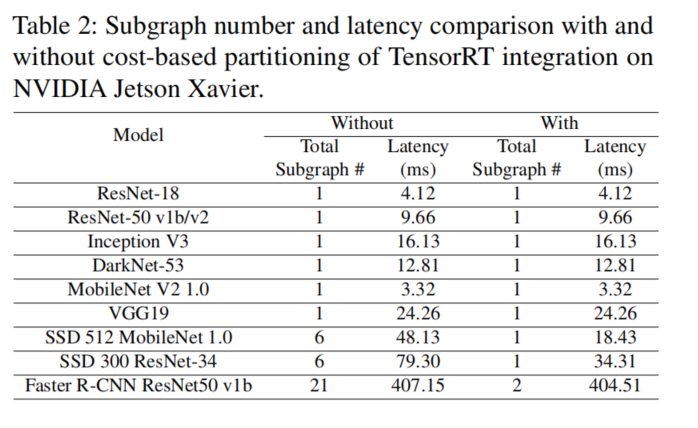
基于成本的划分之后,一些可以卸载到TensorRT算子,但是并不是计算密集型(transpose、max、reshape),仍旧在host上执行,以减小调用以及数据传输开销。
Xilinx Edge and Cloud FPGAs
该案例关于Xilinx Vitis AI,这是Xilinx的部署栈,用于Xilinx边缘设备和Alveo加速卡。Vitis AI具有自定义的bit流来表示划分的子图,且使用Vitis AI自定义运行时模块解释bit流,并向部署到的Xilinx DPU调度算子。由于Xilinx DPU只专注定点计算,因此该案例的集成包含了定制的量化。Vitis AI运行时将数据输入Xilinx的量化器,计算量化的scale和零点。其余部分仍是全精度浮点数,只有卸载到FPGA的部分执行定点运算。
下表为该案例的性能对比,baseline是TVM内置的LLVM代码生成,运行平台在Intel Xeon Gold 6252 CPU。
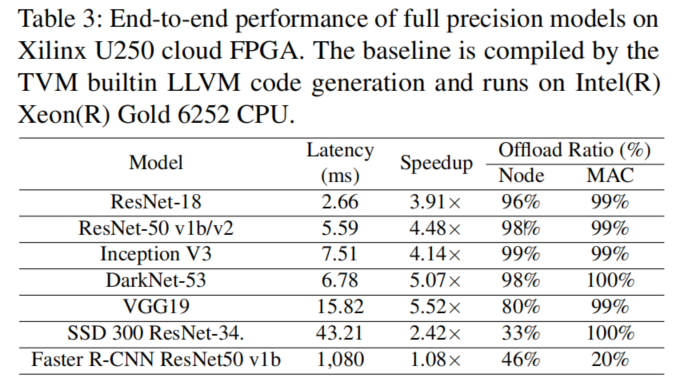
对于Faster RCNN ,Vitis AI在当时只支持模型中的一个内核,将其backbone Resnet-50卸载到FPGA,其他NMS(非极大抑制)、split等无法卸载。
将模型执行时间分解来评估卸载开销。与为每个子图构建一个执行引擎的TensorRT不同,Xilinx Vitis-AI运行时能够直接在其DPU上执行该图。(这句话不太明白,TensorRT的每个子图执行都要初始化一些东西吗??)
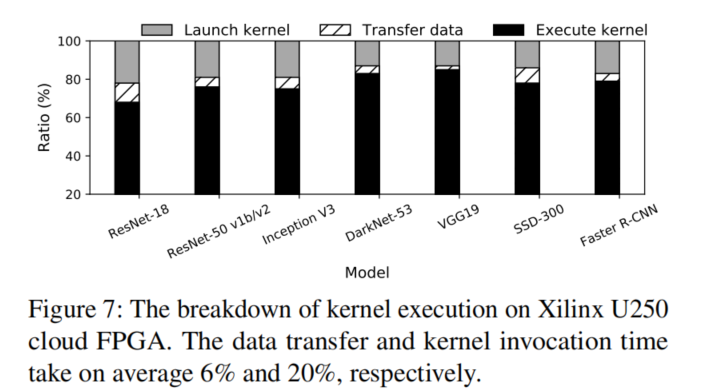
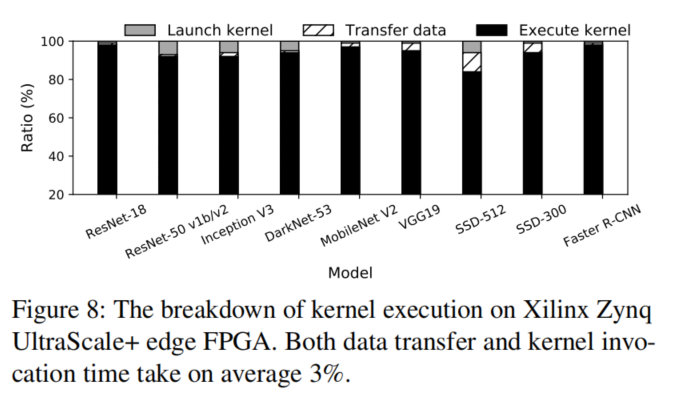
两款FPGA在启动内核上占的比例区别较明显,这是因为边缘设备算力弱,计算时间长导致计算耗时相对比例更高导致的吗???